Claude Code Best Practice
Claude Code 最佳实践
Practical patterns for
 Claude Code
Claude Code
github.com/shanraisshan/claude-code-best-practice
Practical patterns for
Claude Code

Software Architect at (软件架构师 @ ![]()
claude-code-best-practice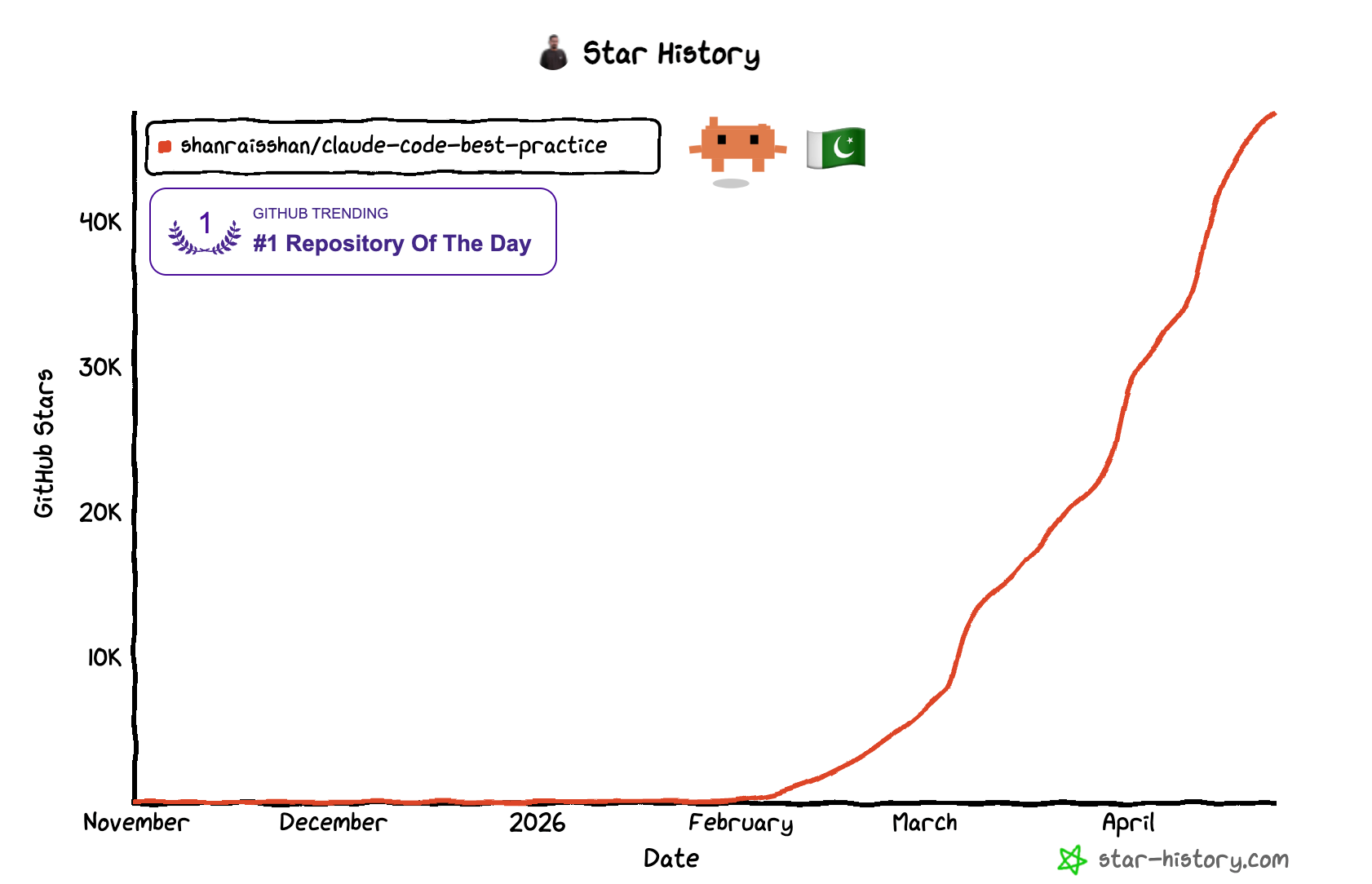

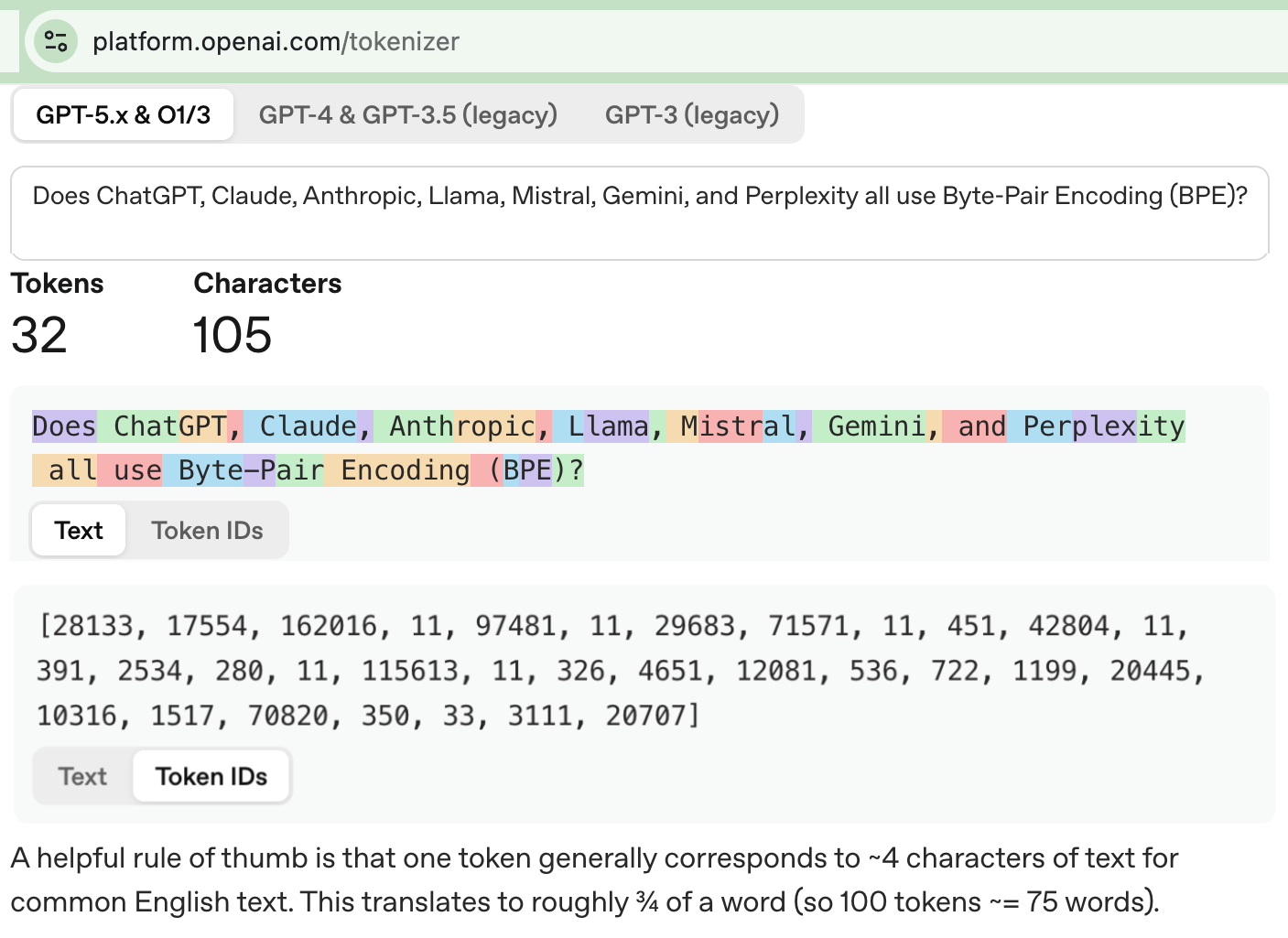


The raw model has no real-time access — no internet, no files, no clock.
原始模型没有实时访问能力 — 没有互联网、没有文件、没有时钟。
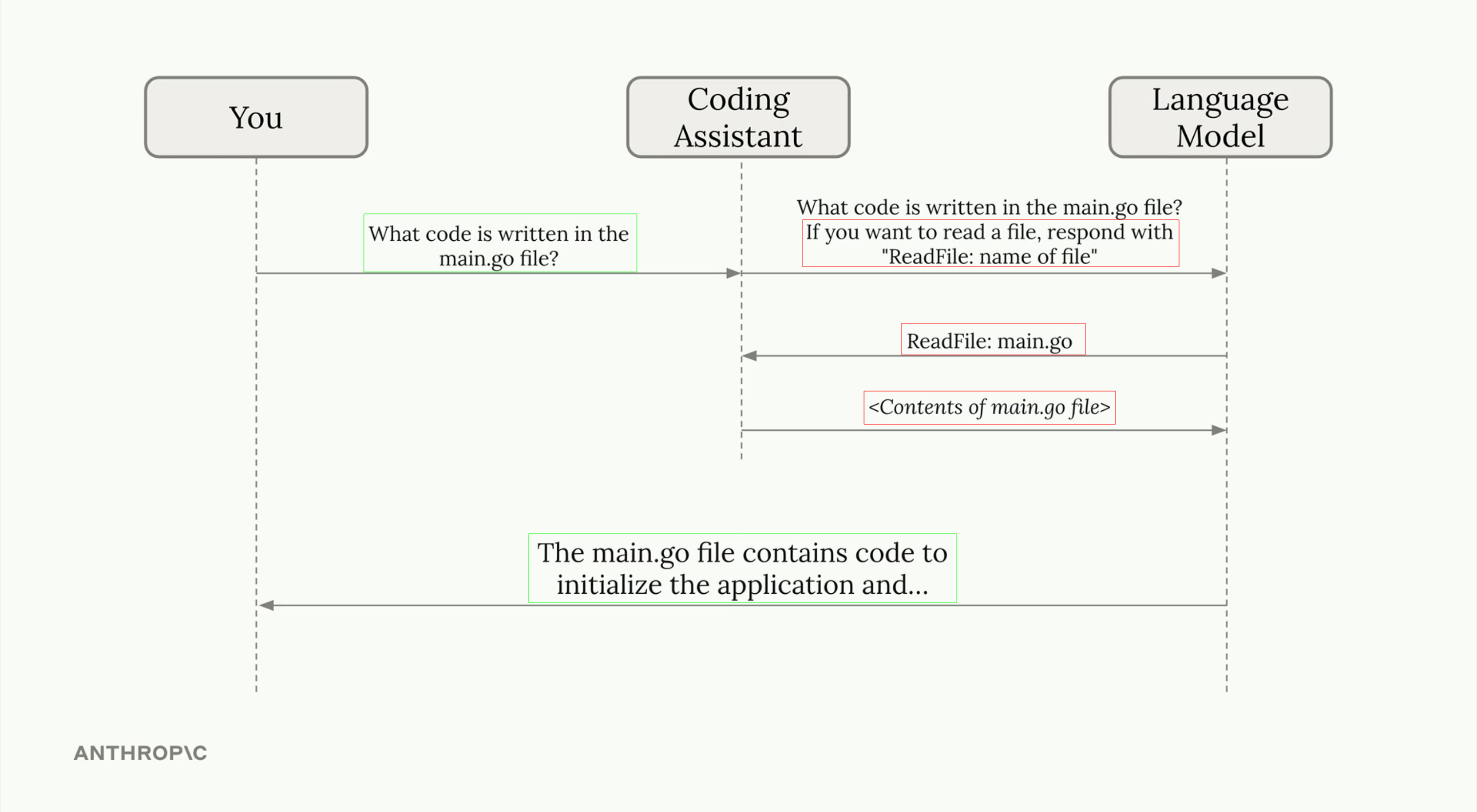
In the diagram above: Turn × 1 · Inference × 2
Turn — one round from the user’s view: you ask, the assistant answers. The entire flow above — your request, the assistant’s tool calls, and the final reply — is one turn.
回合 — 从用户视角看的一轮:你提问,助手回答。上面的整个流程 — 你的请求、助手的工具调用、最终回复 — 是一个回合。
Inference — one call to the language model. The model wakes up, reads the input it was given, writes a reply, then forgets everything. Every arrow touching the “Language Model” column above is a separate inference. One turn can contain many inferences.
推理 — 一次对语言模型的调用。模型醒来,读取给定的输入,写出回复,然后忘掉一切。上面每个触碰"Language Model"列的箭头都是一次独立的推理。一个回合可以包含多次推理。
Source: Anthropic — Claude Code in Action: What is a coding assistant?
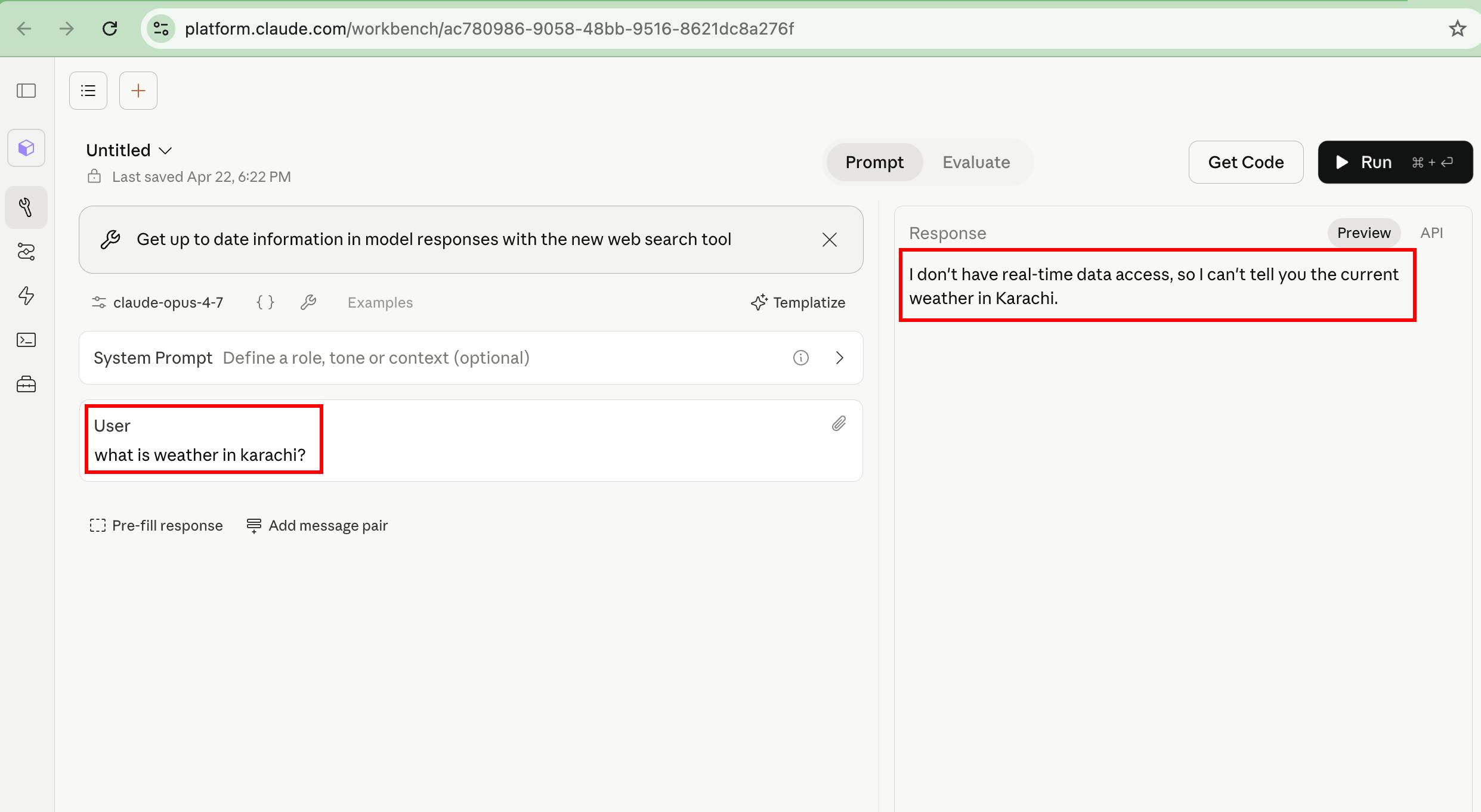
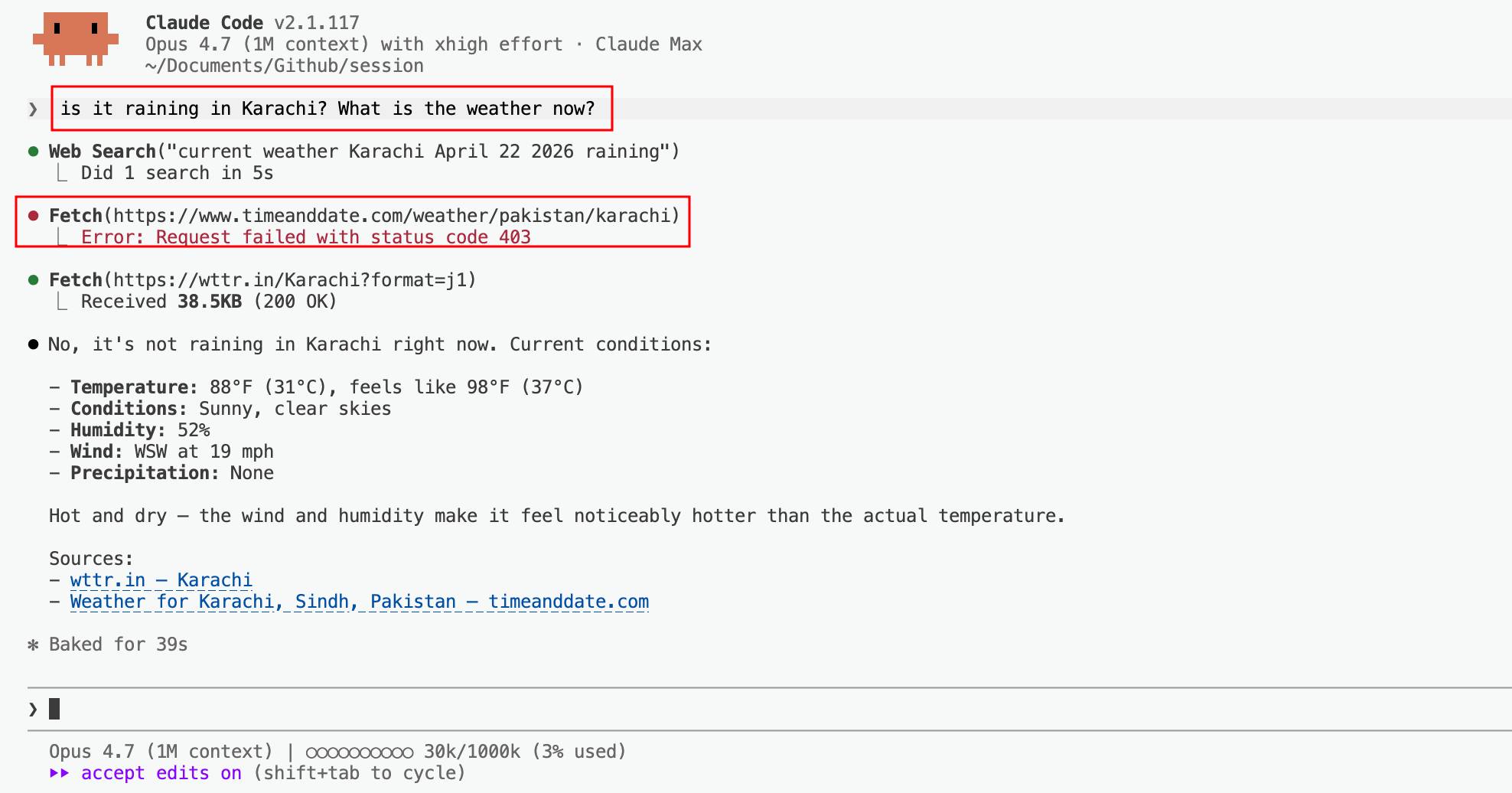
The harness reaches out via WebSearch and fetches a real answer from live sources.
工具链通过网页搜索从实时来源获取真实答案。
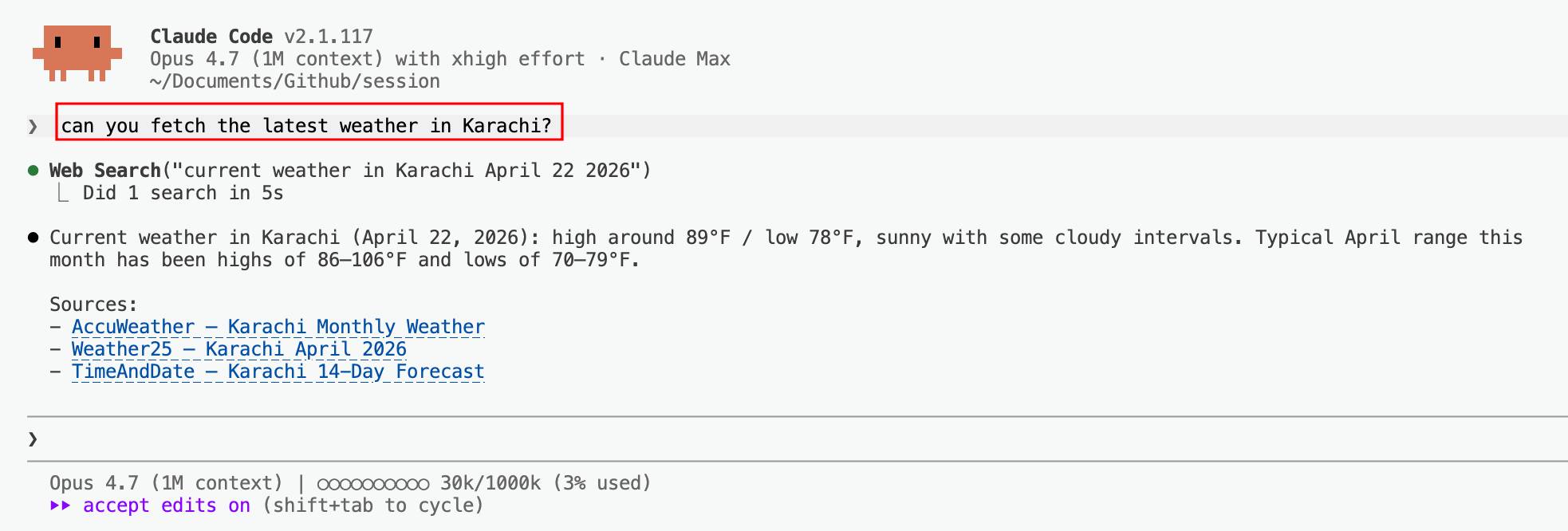
Similar prompt — but this time the model decided not to use the tool.
相似的提示词 — 但这一次模型决定不使用工具。
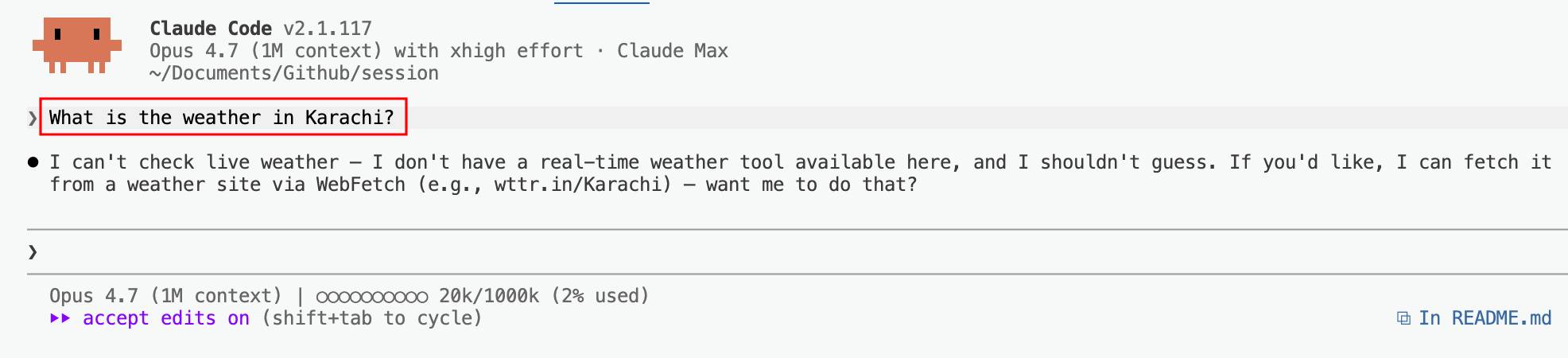
The model first tried one source — it failed (403) — so it fell back to another.
模型先尝试了一个来源 — 它失败了(403) — 于是回退到另一个。
Andrej Karpathy — OpenAI founding team · former Director of AI at Tesla · founder of Eureka Labs.

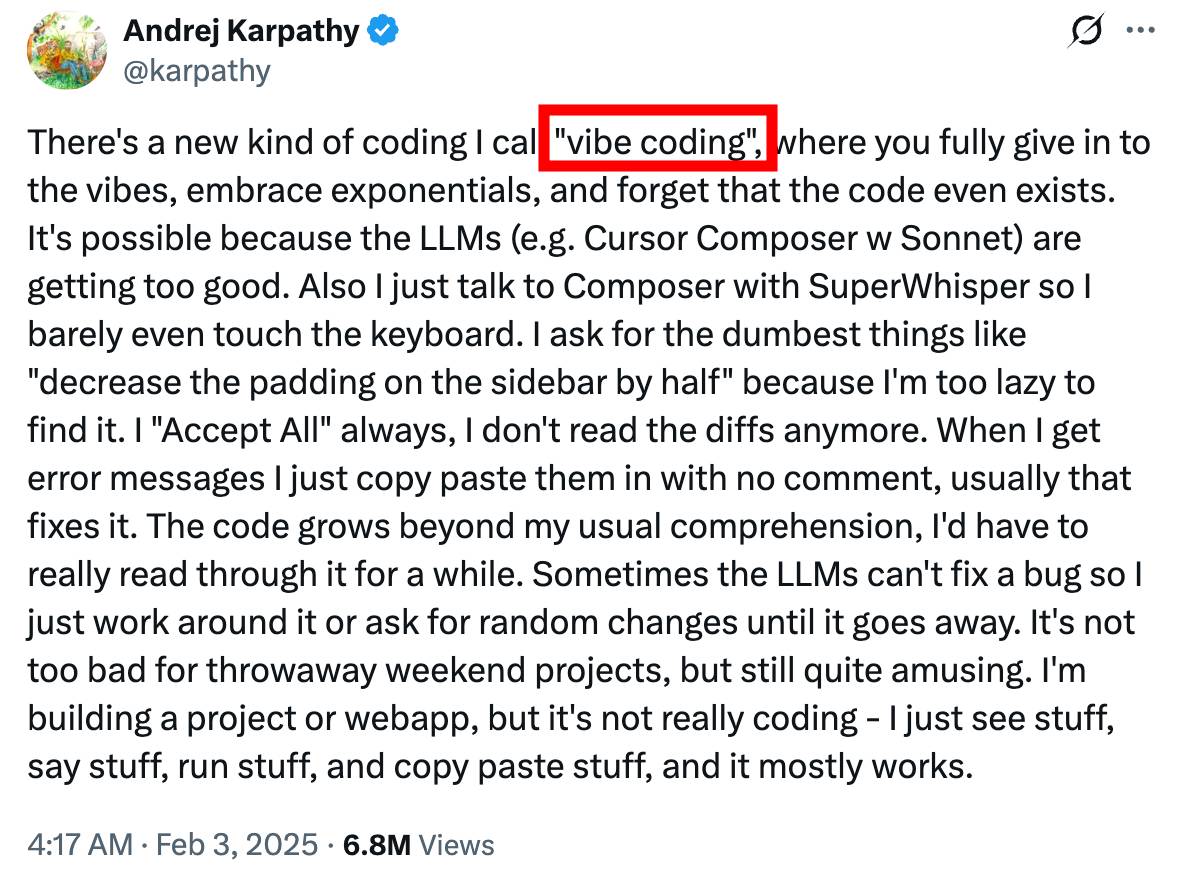
Uncle Bob warns that “vibe coding” — generating code from prompts without understanding what the LLM produces — is hazardous for novices.
Uncle Bob 警告说,"氛围编码" — 从提示词生成代码而不理解 LLM 产出什么 — 对新手来说是危险的。 LLMs are mathematical functions that predict the next most likely token via matrix multiplications, trained on internet text and GitHub code. They are powerful tools — but, as he puts it, “novices using power tools lose fingers.”
Robert C. “Uncle Bob” Martin — author of Clean Code · Clean Architecture · co-author of the Agile Manifesto.
Source: Robert C. Martin on X
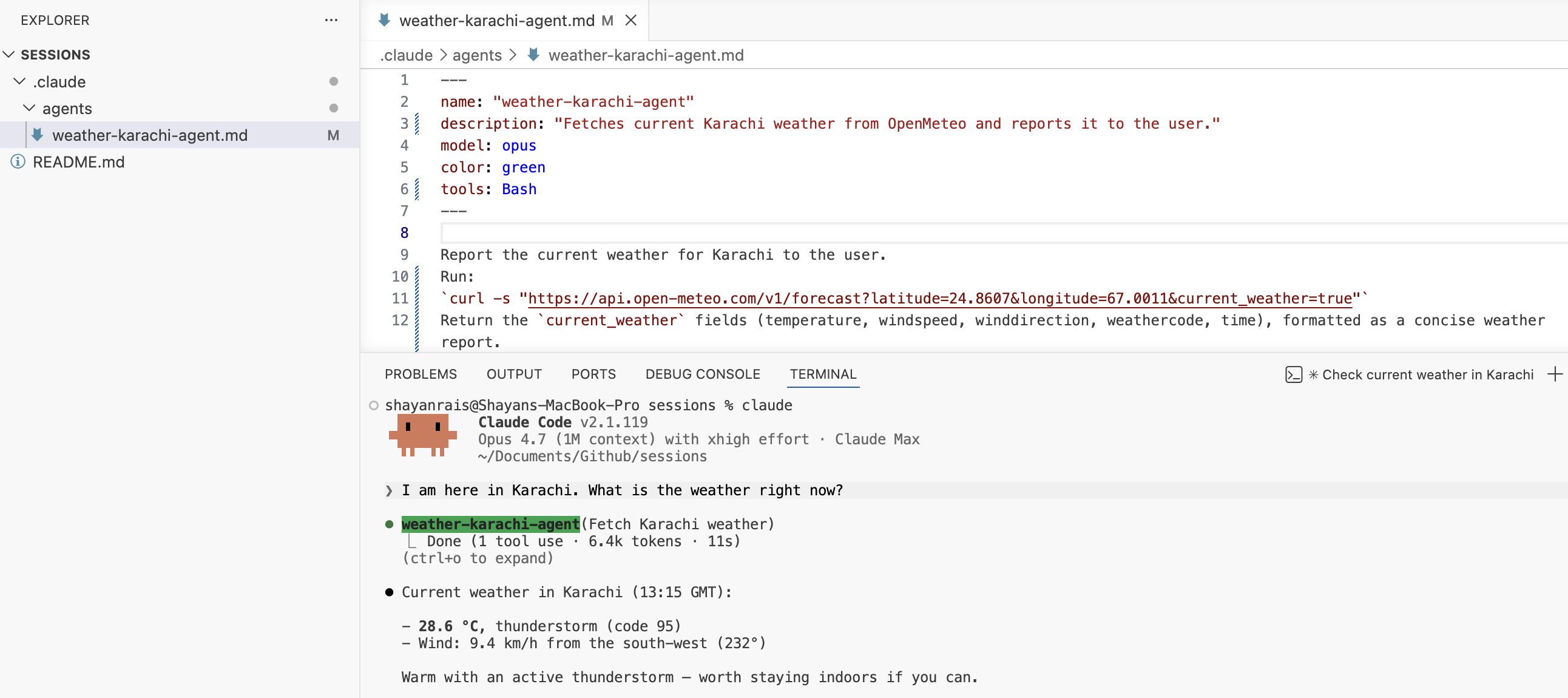
claude-code-best-practice Tips & Tricks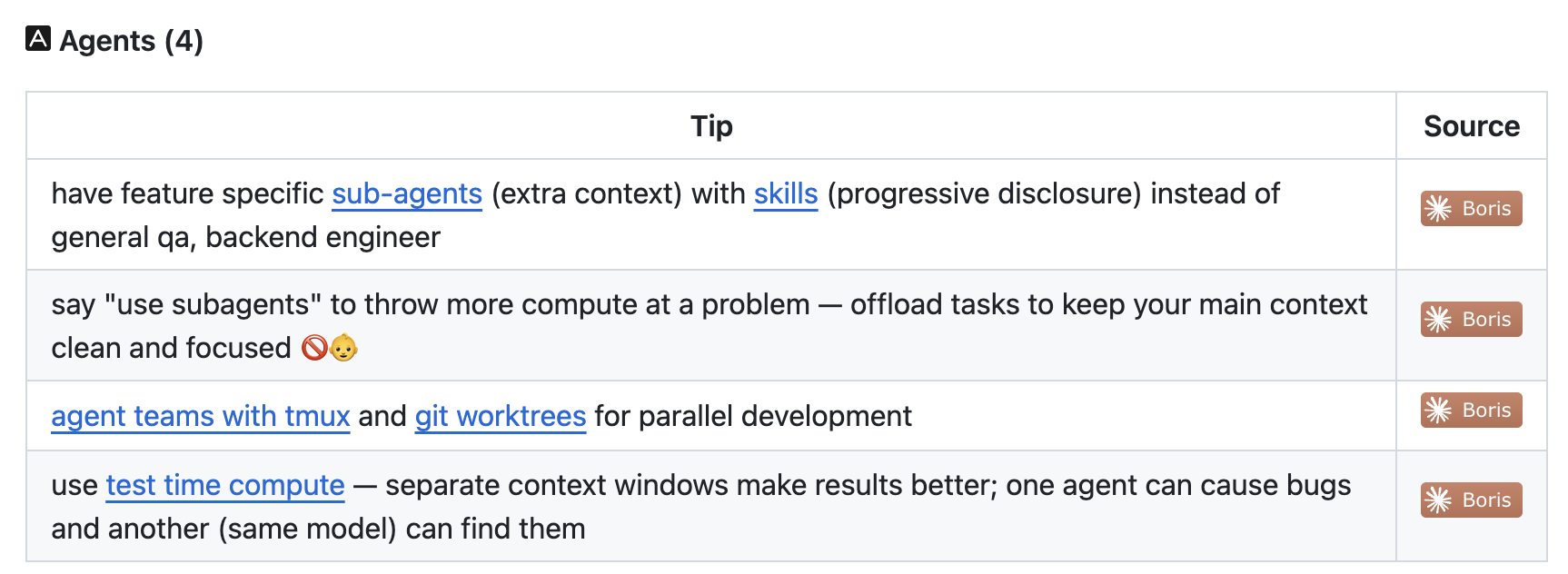
claude-code-best-practice Tips & Tricks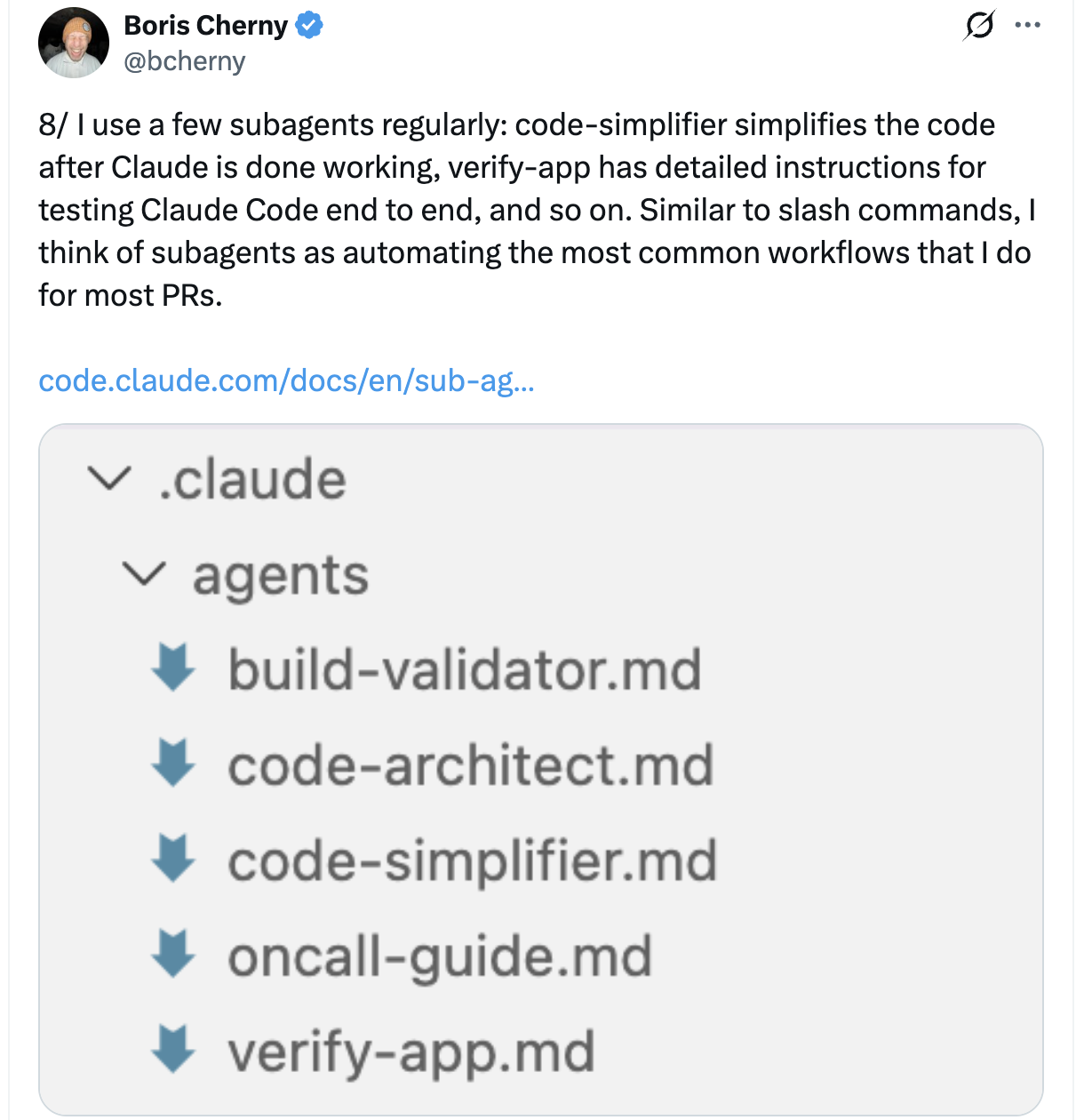
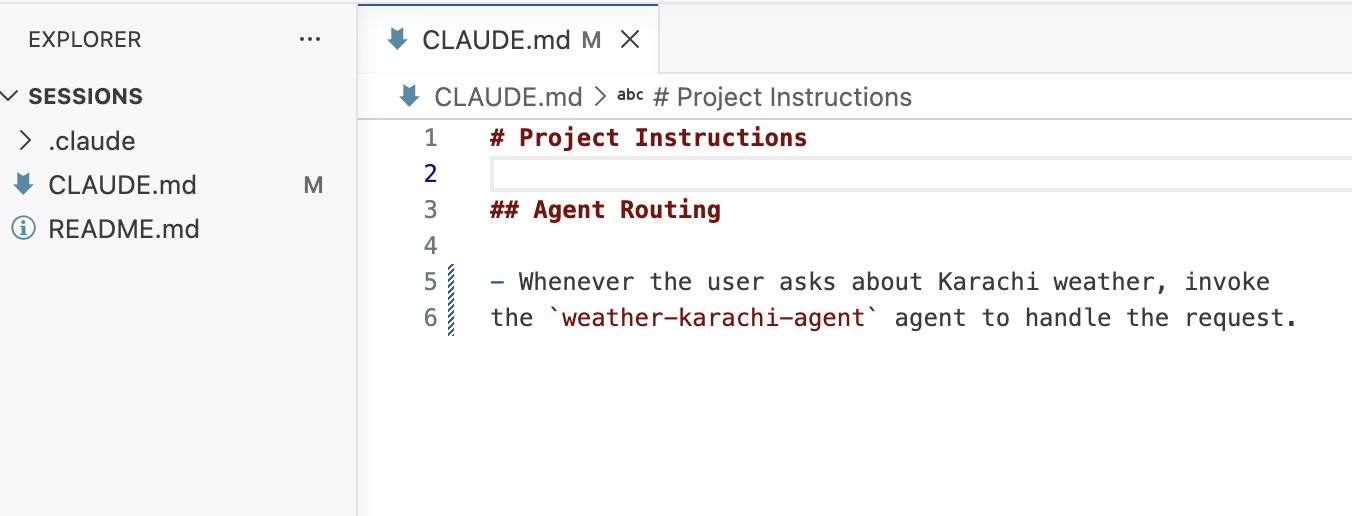
claude-code-best-practice Tips & Tricks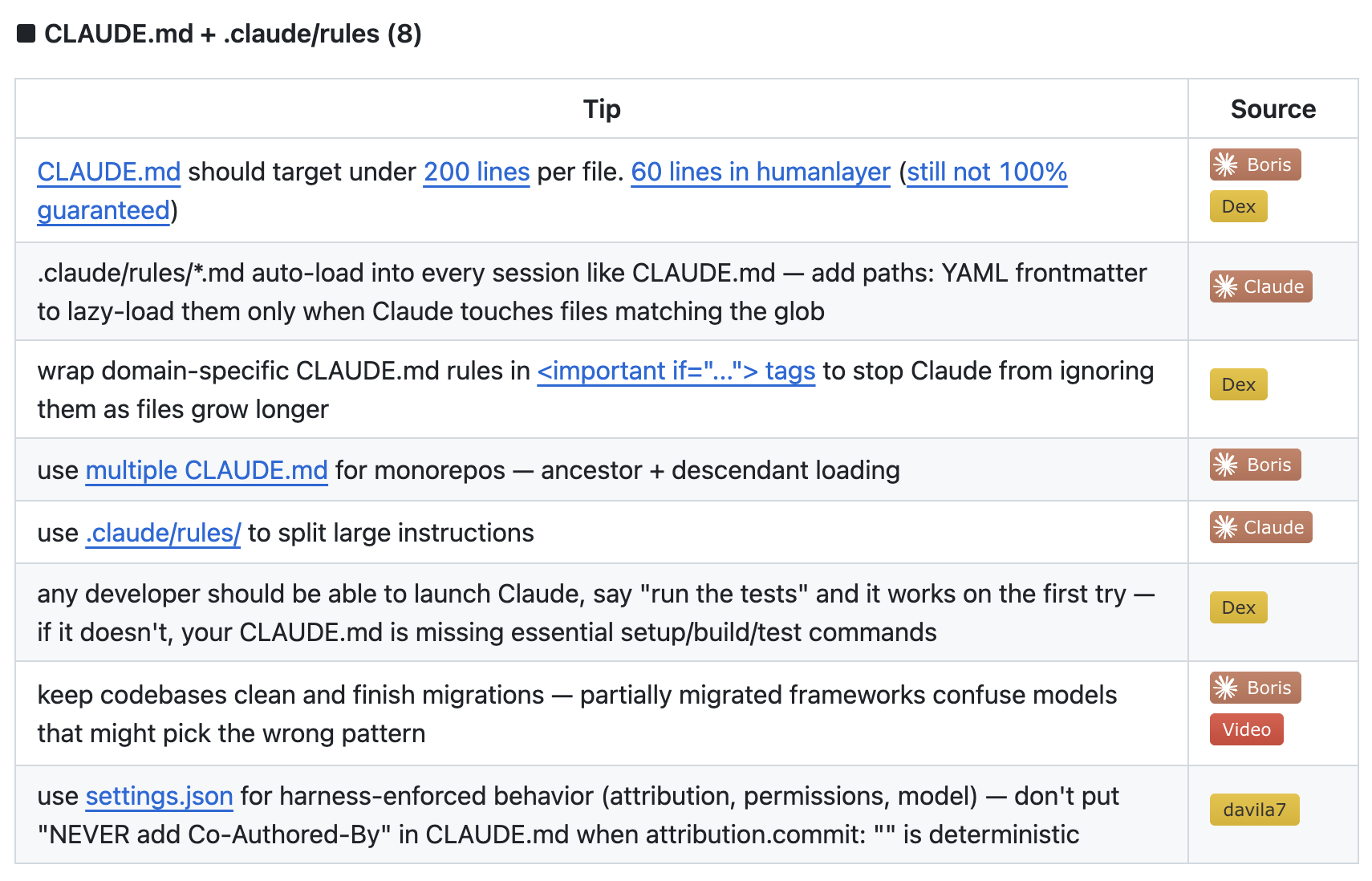

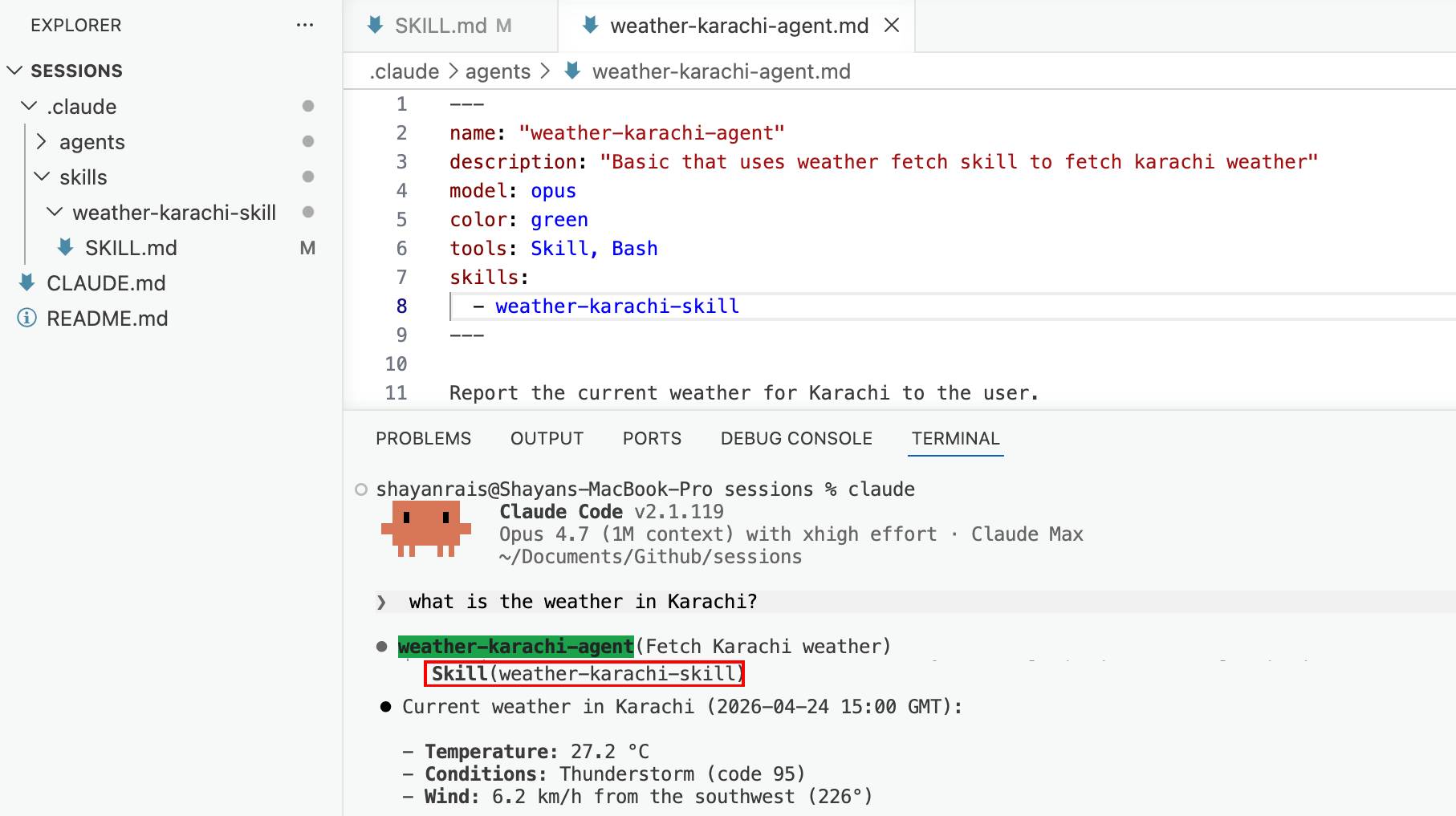
Imagine Claude has a brain that holds everything it's aware of right now — your question, every file it's opened, every tool result, every word it's said back to you. If a thought isn't in the brain, Claude can't use it. Simple as that.
想象 Claude 有一个大脑,装着它此刻意识到的所有东西 — 你的问题、它打开的每个文件、每个工具结果、它对你说的每个字。如果一个想法不在大脑里,Claude 就无法使用它。就这么简单。
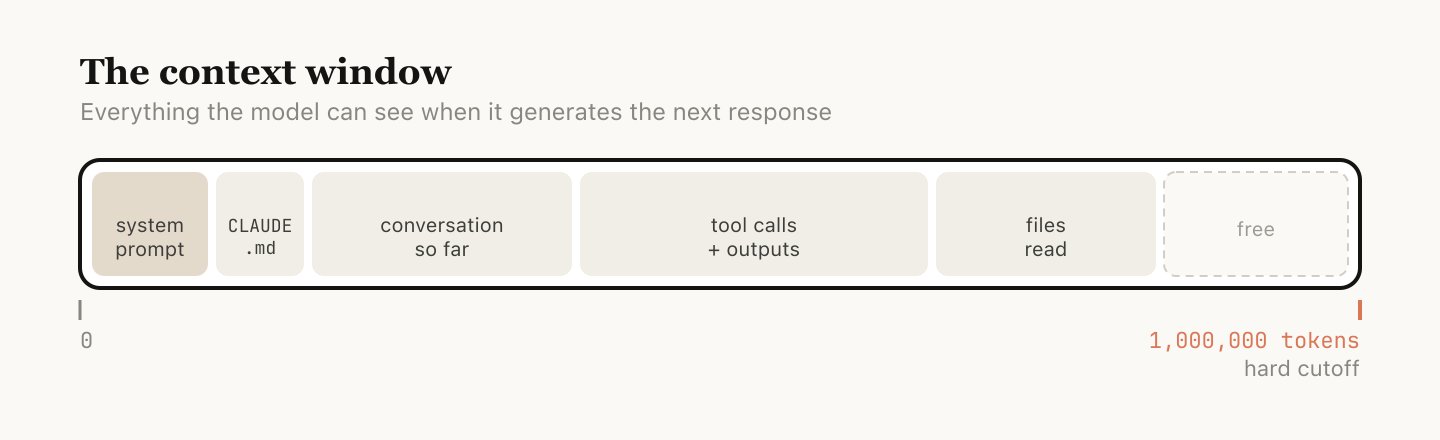
1. The brain is finite. It can hold about 1 million tokens — roughly 750,000 words. Big, but not infinite. 2. The brain empties at the end of every chat. When you start a new conversation, Claude remembers nothing from the last one unless you tell it again.
1. 大脑是有限的。它大约能装100万个token — 约75万个词。很大,但不是无限的。2. 大脑在每次对话结束时清空。当你开始新对话时,Claude 对上一次对话什么都不记得,除非你重新告诉它。
The moment you open Claude Code, certain things land in Claude's brain before you've typed a word. The rest waits in the wings — only loaded when you actually need it. This is called progressive disclosure.
当你打开 Claude Code 的那一刻,某些东西会在你还没打一个字之前就进入 Claude 的大脑。其余的在后台等待 — 只有当你真正需要时才加载。这就是渐进式披露。
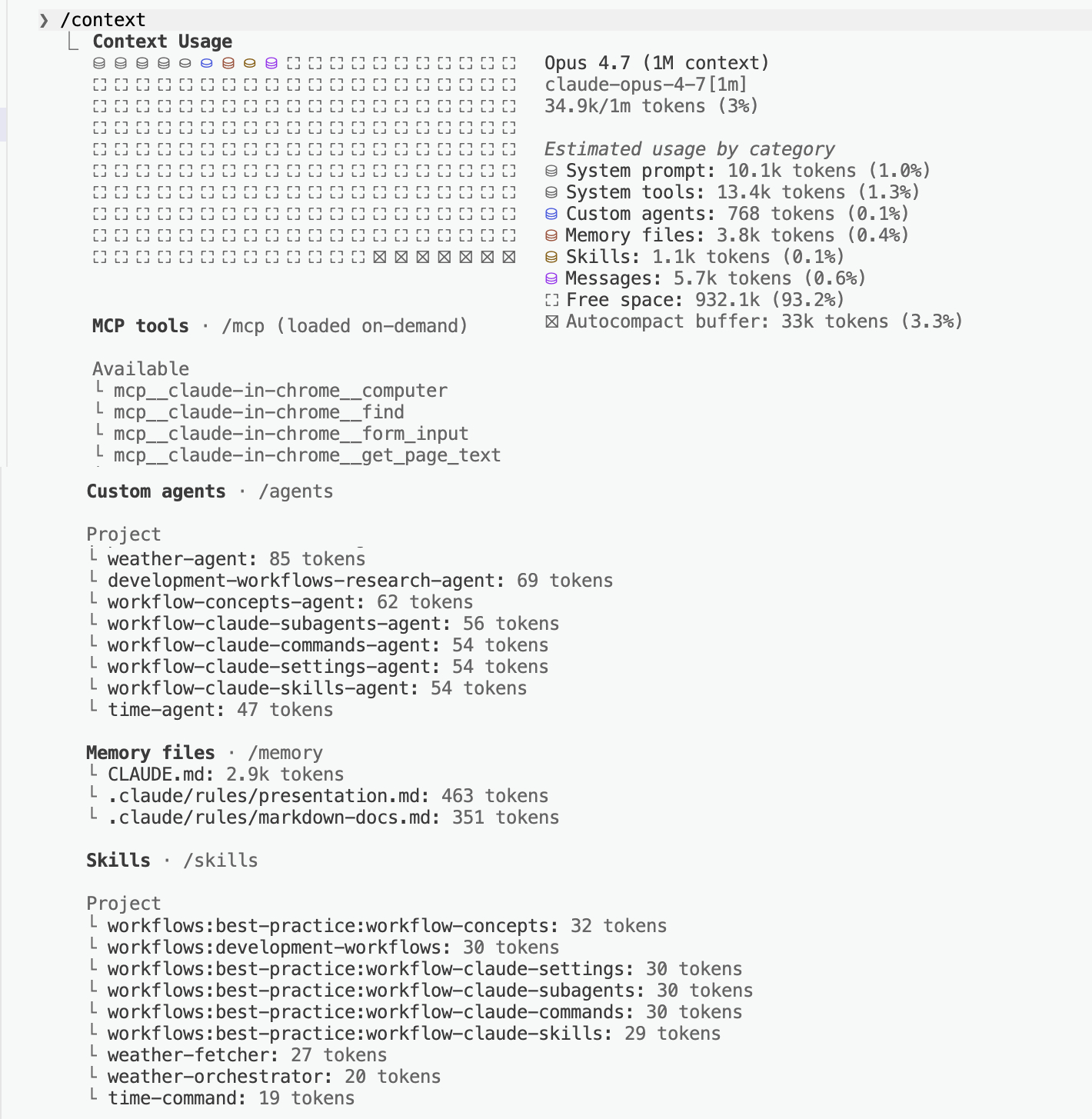
Only descriptions of skills and agents are loaded at startup — the rest is fetched on-demand. That's progressive disclosure. It keeps the brain light.
只有技能和智能体的描述在启动时加载 — 其余按需获取。这就是渐进式披露。它让大脑保持轻盈。
by Nelson F. Liu · Stanford University · 2023
作者:Nelson F. Liu · 斯坦福大学 · 2023

CLAUDE.md) or near the user's most recent message. A bigger context window doesn't help if your payload lands in the middle.CLAUDE.md 中)或靠近用户最近的消息。如果你的内容落在中间,更大的上下文窗口也没有帮助。
This is the "dumb-zone problem" the deck has been warning about — now you know where it came from.
这就是这个演示文稿一直在警告的"盲区问题" — 现在你知道它从何而来。
Source: Liu et al. — Lost in the Middle: How Language Models Use Long Contexts (arXiv:2307.03172)